
We present a new method for improving the performances of variational autoencoder (VAE). In addition to enforcing the deep feature consistent principle thus ensuring the VAE output and its corresponding input images to have similar deep features, we also implement a generative adversarial training mechanism to force the VAE to output realistic and natural images. We present experimental results to show that the VAE trained with our new method outperforms state of the art in generating face images with much clearer and more natural noses, eyes, teeth, hair textures as well as reasonable back- grounds. We also show that our method can learn powerful embeddings of input face images, which can be used to achieve facial attribute manipulation. Moreover we propose a multi-view feature extraction strategy to extract effective image representations, which can be used to achieve state of the art performance in facial attribute prediction.
- Variational Autoencoder (VAE) has become a popular generative model, allowing us to formalize this problem in the framework of probabilistic graphical models with latent variables. By default, pixel-by-pixel measurement like L2 loss, or logistic regression loss is used to measure the difference between the reconstructed and the original images. Such measurements are easily implemented and efficient for deep neural network training. However, the generated images tend to be very blurry when compared to natural images. This is because the pixel-by-pixel loss does not capture the perceptual difference and spatial correlation between two images.
- In this paper, we propose a new method to train the variational autoencoder (VAE) to improve its performance. In particular, we seek to improve the quality of the generated images to make them more realistic and less blurry. To achieve this, we employ objective functions based on deep feature consistent principle and generative adversarial network instead of the problematic per-pixel loss functions. The deep feature consistent can help capture important perceptual features such as spatial correlation through the learned convolutional operations, while the adversarial training helps to produce images that reside on the manifold of natural images. The overview of our method is shown in Figure 1.
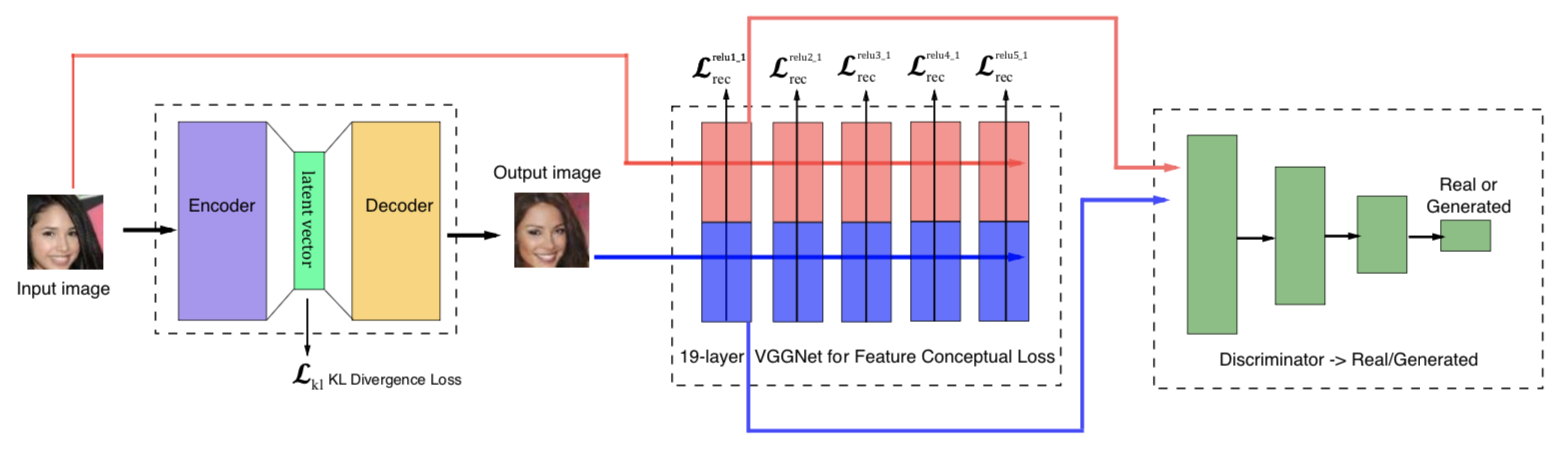
Figure 1 The overview of our method
- Experiments
1 Qualitative results for image generation. We compare the perceptual quality arbitrary image generation and natural image reconstruction for different generative models. As shown in Figure 2 and Figure 3. Our method can generate more consistent and realistic human faces with much clearer noses, eyes, teeth, hair textures as well as reasonable backgrounds.

Figure 3. Face images generated from 100-dimension latent vector

Figure 4. Face images reconstructed by different models.
3.2 Facial attribute manipulation. we seek to find a way to control a specific attribute of face images. In this paper, we conduct experiments to manipulate the facial attributes in the learned latent space of VAE-WGAN. Figure 5 shows the results for the 6 attributes, i.e., Bald, Black hair, Eyeglass, Male, Smiling, and Mustache. We can see that by adding a smiling vector to the latent representation of a non-smiling man, we can observe the smooth transitions from non-smiling face to smiling face.

Figure 5. Vector arithmetic for visual attributes.
- Reference
Xianxu Hou, Ke Sun, Linlin Shen, Guoping Qiu. “Improving Variational Autoencoder with Deep Feature Consistent and Generative Adversarial Training”, (2019) Neurocomputing, 341, 183-194.