
Our VADIV database can be downloaded from the following link:
Database:
Link:https://pan.baidu.com/s/11D3igdSFudR-zrWwXSG0aA
Verification Code:yx66
Code & Model:
Link: https://pan.baidu.com/s/1c5qqh0U1aZq4EbGA1fNFZQ
Verification Code: f1jo
These can also be downloaded on github:
https://github.com/TIM-ysh/ITM-VQA
Ⅰ、More details about ITM-HDR-Videos dataset.
Visually, the ITM algorithm changes the dynamic range, colour representation and local detail of the SDR video, and we will show some visual examples from the ITM-HDR-Videos dataset in these areas. In addition we will also show examples of similar MRS but with very different MAS. It is worth noting that HDR video data cannot be stored correctly on web pages, and that web pages in general are displayed based on srgb. Therefore, we show these examples with the same contrast and saturation stretching to obtain a visual effect as similar as possible to viewing on an HDR display.
1、All SDR videos in ITM-HDR-Videos dataset .

2、More details about the ITM-HDR-videos generation from ITM algorithms.

3、Different ITM algorithms lead to differences in dynamic range.

4、Different ITM algorithms lead to differences in colorfulness.

5、Different ITM algorithms lead to differences in local details.


6、Example of flicking caused by ITM.


7、The same MRS with different MAS.

Ⅱ 、More detail about OUR VQA MODEL
1、Detail about the data preprocess.
SDR video frames are normalized from [0,255] to [0,1] when pre-trained and online learning, while HDR video frames are normalized from [0,1023] to [0,1].
2、 More detail about feature Normalization, Concatenation & Regression.
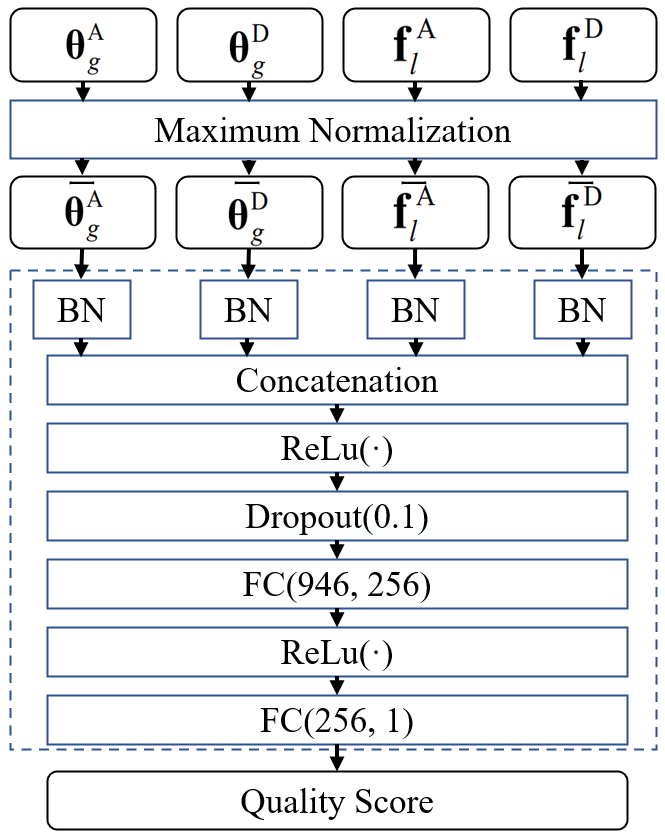
The specific implementation of Maximum Normalization is as follows:


3、Computational complexity analysis with deep learning models in comparison methods.
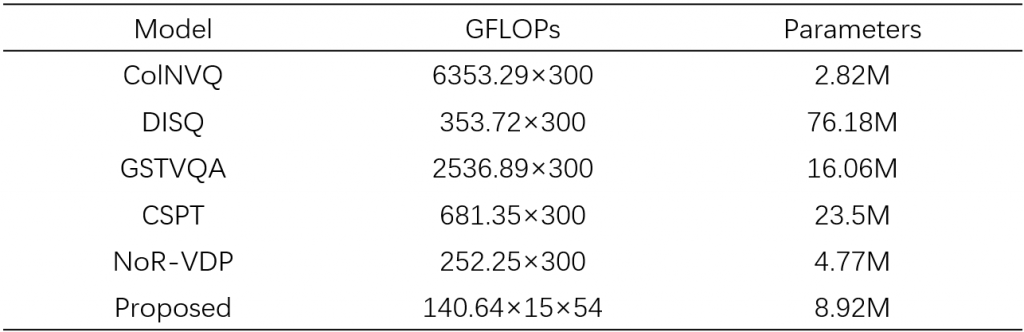
The computational complexity are computed base on a 4K 50fps HDR video with
6 seconds.