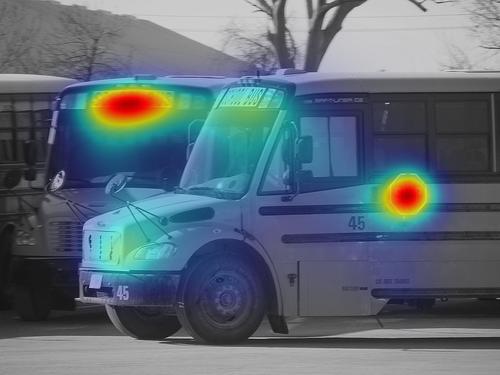
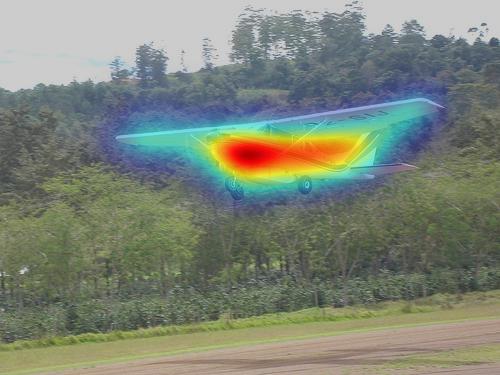
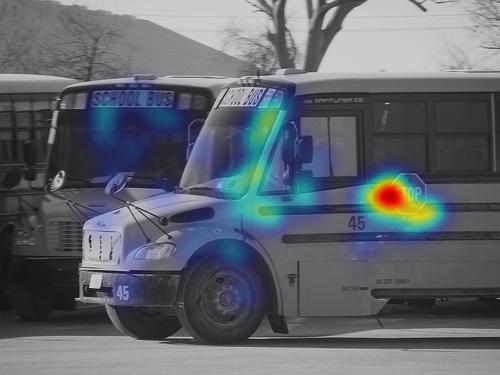
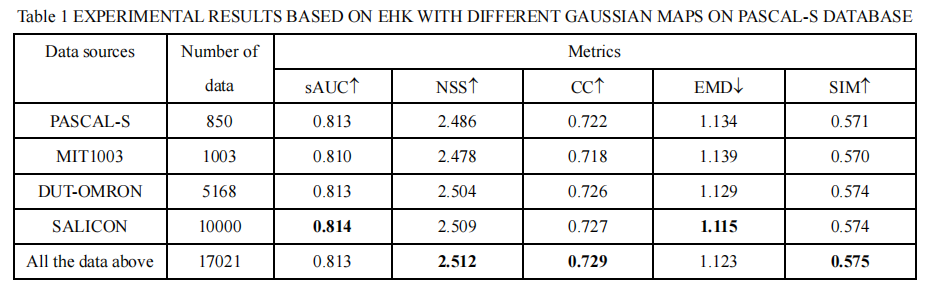
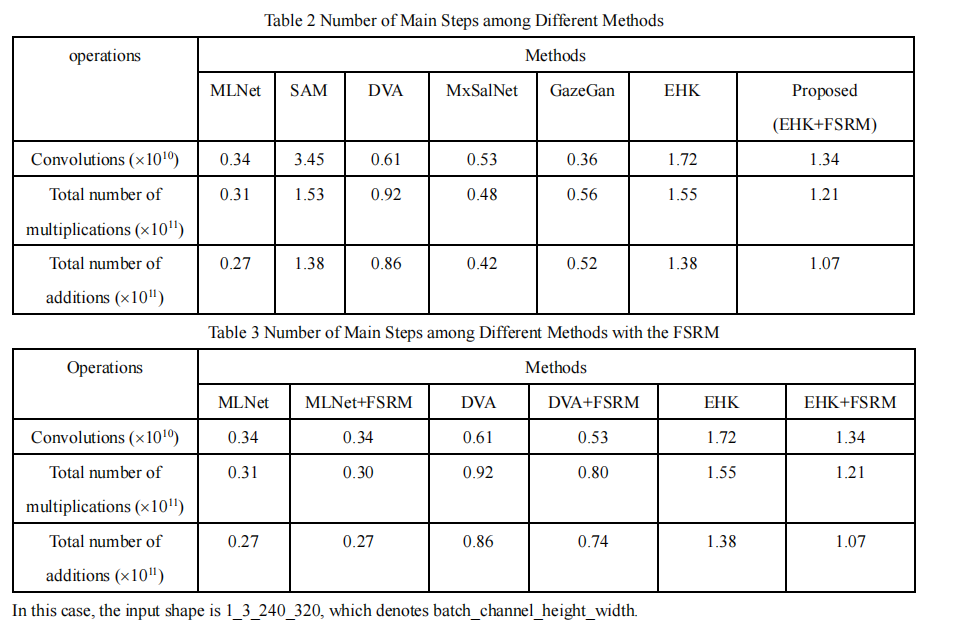
×According to the work of David Marr on vision [X1], a full analysis of an information processing system involves three levels: computational, algorithmic, and implementational. The computational level describes the information processing problem to be solved. The algorithmic level describes the steps that need to be carried out to solve the problem. And the implementational level deals with physical realization of the system. Based on these terminologies, we compare the algorithmic steps of different saliency prediction models. As shown in our manuscript, the most competitive models are based on deep networks, where the main steps include the operations of convolutions, full connections (i.e., matrix transformation), and activation functions (e.g., ReLu and sigmoid). In particular, the number of convolution operations is much larger (not in the same order of magnitude) than the other operations. Therefore, we only perform a comparison between our model and competitors based on the number of convolution operations, as shown in Table 2. In addition, given a convolution kernel of size k*k, one convolution contains k*k multiplications and k-1 additions without considering the bias. Thus, we can further calculate the total number of multiplications and additions. From Table 2, we can see that SAM contains the most algorithmic steps, and MLNet contains the least steps. The EHK model also contains a lot of convolutions. However, compared with EHK, our proposed model reduces the number of convolutions about 3.8*109, which is about 22% reduction. This benefits from the feature selection of FSRM. In the proposed model, the number of feature channels is halved by each FSRM, greatly reducing the amount of convolutions. The reduction in the number of operations can also be reflected in the total number of multiplications and additions. Moreover, we perform another comparison in the other hierarchical fusion model including MLNet and DVA by adding FSRM, as shown in Table 3. From Table 3, we can see that the number of operations is effectively reduced by adding the proposed FSRM in the MLNet and DVA.